MTPLX可能是Apple Silicon上最快的LLM推理引擎
引言:本地大模型的新选择
随着 Qwen、Gemma、Llama 等大语言模型在 Apple Silicon 上的蓬勃发展,Mac 用户有了越来越多的本地推理选择。从最早期的 llama.cpp,到后来基于 MLX 的 mlx-lm、omlx,以及专门为 Apple Silicon 优化的各种推理引擎——但大多数都在做同一件事:用标准**自回归解码(Autoregressive Decoding)**逐 token 地生成文本。
逐 token 生成意味着每一步都要等前一个 token 完成后才能开始下一个。GPU 的计算单元在等待的过程中得不到充分利用。而 MTPLX 的出现,彻底改变了这一点——它利用模型自带的 MTP(Multi-Token Prediction,多 token 预测) 头,让模型一次预测多个候选 token,然后批量验证,在不改变输出分布的前提下实现大幅加速。
MTPLX 是什么
MTPLX(由 Youssof Altoukhi 开发)是一个基于 Apple MLX 框架、为 Apple Silicon 原生打造的 LLM 推理引擎。它的核心理念是:利用现代模型(如 Qwen 3.5/3.6)内置的 MTP 头进行投机解码(Speculative Decoding),无需外部草稿模型(draft model),即可实现 1.6x~2.24x 的解码速度提升。
- 开源协议:Apache 2.0
- 开发语言:Python(基于 MLX)
- 当前版本:v1.0.3
- 运行环境:macOS 14+,Apple Silicon(M1 及更新版本)
- GitHub:github.com/youssofal/MTPLX
- 🌟 GitHub Stars:700+(快速增长中)
核心特性与优势
1. 🚀 Native MTP 投机解码——这才是真正的创新
这是 MTPLX 最核心的技术亮点。传统投机解码需要两个模型:一个轻量级 draft 模型快速生成候选 token,再由目标模型验证。这不仅增加了显存占用(两个模型),还得额外维护一个 draft 模型。
MTPLX 的做法完全不同:它使用模型自己携带的 MTP 头。Qwen 3.5 / 3.6 系列模型在训练时就已经内置了额外的输出头,能够一次预测多个未来的 token。MTPLX 激活了这些没有被其他推理引擎使用的 MTP 头:
- 模型通过 MTP 头快速生成多个候选 token
- 在一步中批量验证所有候选 token
- 只保留通过精确拒绝采样的 token
- 因此每一步都能多生成几个 token,而输出分布与标准解码绝对一致
这意味着:同样的模型、同样的采样参数、同样的输出质量,只是更快。
2. 🎯 精确的拒绝采样——速度快,质量不降
MTPLX 的整个加速建立在 Leviathan 和 Chen(2023)提出的投机采样数学基础上,配合残差修正(residual correction)。无论你是用 temperature=0.6 还是 temperature=1.0,模型产生的输出分布与标准自回归解码完全一致。
不是近似,不是贸易-off,是数学上保证的「更快且完全一样」。
3. 🔧 Auto-tune:为你的 Mac 自动找到最快的解码深度
每台 Mac 的芯片、内存带宽、散热情况都不一样。MTPLX 的 mtplx tune 命令会:
- 加载你的模型
- 在每个 MTP 深度(D0/AR、D1、D2、D3)上分别运行基准测试
- 锁定风扇确保时序准确
- 自动选择在你机器上最快的深度并保存
实测结果(M5 Pro, 48GB 统一内存, Qwen3.6-35B-A3B):
| 模式 | 解码速度 | 加速比 |
|---|---|---|
| AR(传统自回归) | 67.5 tok/s | 1.00x |
| MTP D1(最佳) | 79.2 tok/s | 1.17x |
| MTP D2 | 75.1 tok/s | 1.11x |
| MTP D3 | 68.3 tok/s | 1.01x |
而在 M4 Mac mini(16GB)上测试 Qwen 9B 模型时,加速效果更为显著:
- AR 基线: 14.4 tok/s
- MTP D1: 23.0 tok/s → 1.6x 提升
作者在 M5 Max 上测试 Qwen 3.6 27B 时更是达到了 2.24x 的惊人提升。
4. 💻 macOS 原生 App + CLI 双模式
MTPLX 提供了两种使用方式:
🖥️ Mac App:从 mtplx.com 下载 DMG,拖入 Applications 即可。App 会自动完成:硬件检测 → 模型推荐 → 下载安装 → Python 引擎配置 → 风扇控制 → PATH 设置。内置的 Dashboard 可以实时查看 tok/s、MTP 接受率、验证流水线和系统状态。还提供了原生 Chat 界面,支持流式输出、思考过程展示、文件附件等功能。
⌨️ CLI:通过 Homebrew 或 pip 安装后,命令行使用:
mtplx start # 交互式启动(选模型、模式,直接聊天)
mtplx serve --port 8000 # API 服务器模式
mtplx tune # 自动调优
mtplx models # 查看缓存的模型
mtplx doctor # 健康检查
5. 🔌 OpenAI & Anthropic 双协议兼容
MTPLX 默认在 127.0.0.1:8000 启动服务器,同时支持 OpenAI 风格的 /v1/chat/completions 和 Anthropic 风格的 /v1/messages API。这意味着:
- Claude Code / Cline 可以直接使用 Anthropic 协议连接
- Open WebUI / OpenCode / Continue 等可以使用 OpenAI 协议连接
- 用
curl或openaiPython 库也完全兼容
6. 🔨 Forge:自己动手打造 MTP 模型
MTPLX 还提供了一个叫 Forge 的工具,可以把 HuggingFace 上的任意模型转换为 MTP 模型:
- 输入 HF 仓库链接
- Forge 将模型转换为 MLX 格式
- 训练 MTP 适配器
- 在你本地 Mac 上 实际测量 加速效果
- 如果确实更快,还可以发布到 HuggingFace 分享
这种「先测再说」的诚实态度贯穿整个项目——不承诺做不到的事。
7. 📦 其他亮点
- 会话持久化:Warm-prefix session bank 让多轮对话保持快速,SSD 缓存支持跨重启恢复会话
- 风扇管理:Sustained Max 模式锁定满速风扇,即使
kill -9也能自动恢复 - 模型兼容性检查:
mtplx inspect将模型分为四级(已验证 / 架构兼容 / 不兼容架构 / 无 MTP 头),拒绝运行未经确认的模型 - AIME 基准测试:内置完全公开提示的 AIME 评测,让你自己打分而不是看别人的排行榜
安装使用过程
以下是完整的安装使用过程,全程在 M5 Pro Mac mini(48GB 统一内存,macOS 26.5.1)上完成。
第一步:下载 App
访问 mtplx.com,下载 DMG 安装包(仅 54MB),拖拽到 Applications 文件夹即可。

第二步:设备检测
启动后,MTPLX 会自动检测你的 Apple Silicon 芯片型号、内存大小、macOS 版本,确认是否满足运行要求。
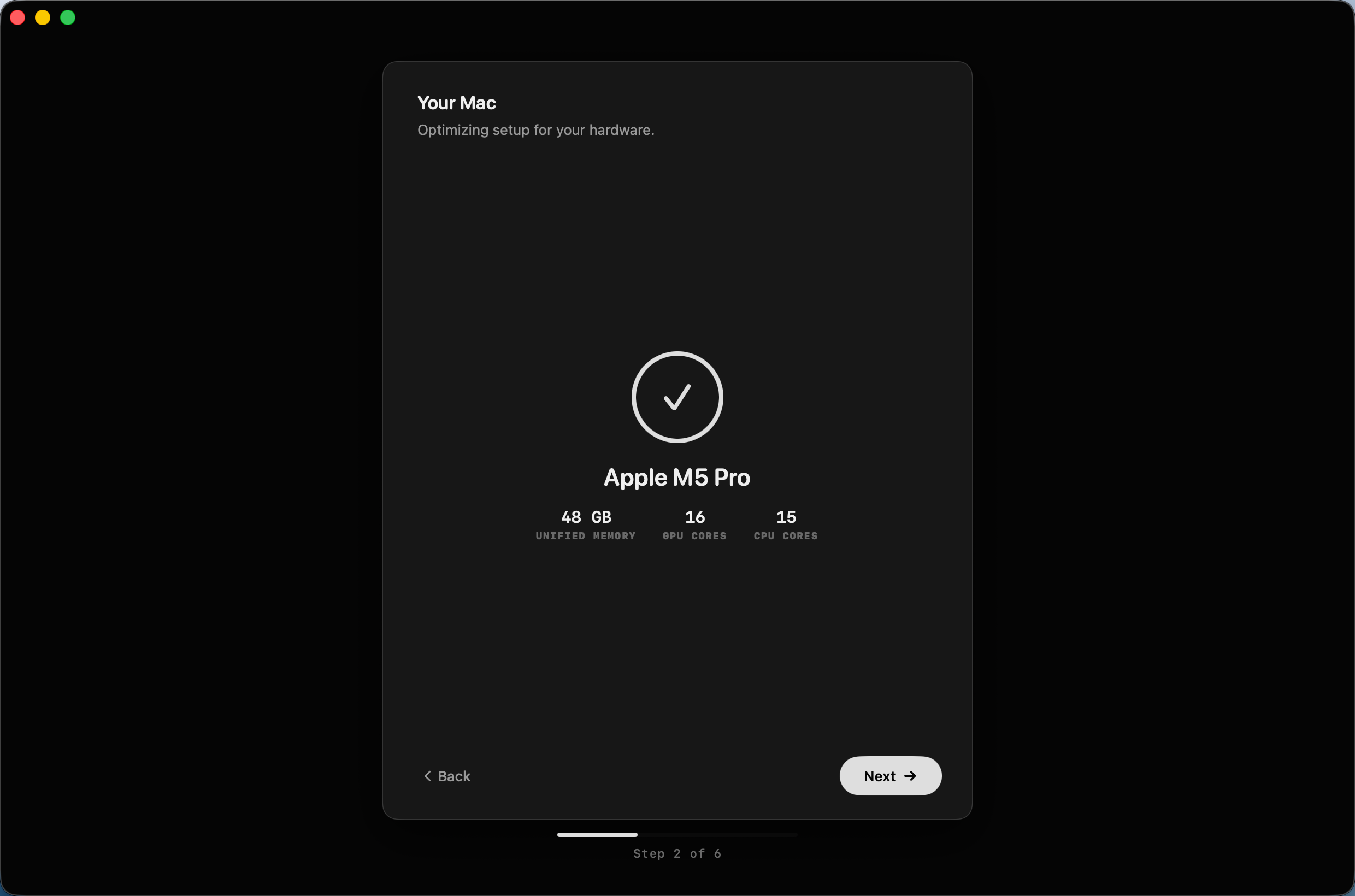
第三步:推荐模型
根据你的硬件配置,MTPLX 会推荐最适合的模型。推荐范围涵盖 Qwen 3.5(4B、9B)、Qwen 3.6(27B、35B MoE)以及 Gemma 4 系列。对于我的 48GB 机器,推荐的是 Youssofal/Qwen3.6-35B-A3B-MTPLX-Optimized-Balance(约 29.7GB)。
第四步:引擎依赖安装
如果是首次使用,MTPLX 会自动创建一个隔离的 Python 虚拟环境,安装 MLX 及其依赖。完全自动,无需手动配置。
第五步:配置模型下载
模型下载支持 HuggingFace 镜像配置,在特定网络环境下非常实用。
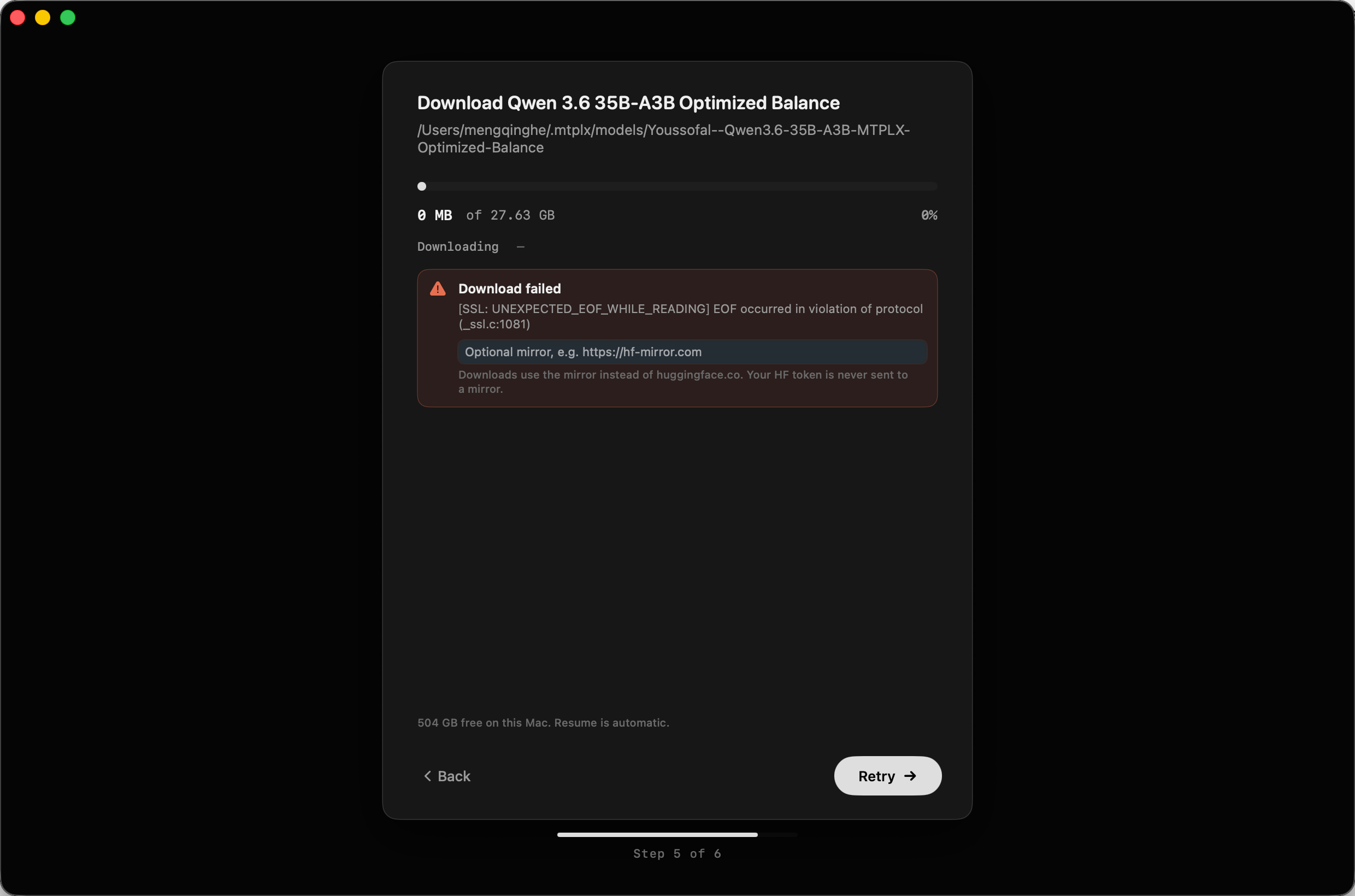
值得一提的是,在测试过程中我发现默认的镜像配置无法成功下载模型。我向作者反馈后,作者迅速响应并修复了这个问题,开源社区的活力可见一斑。
第六步:运行与监控
模型下载完成后即可运行。Dashboard 会实时显示:
- 实时解码速度(tok/s)
- MTP 各深度接受率
- GPU 和内存占用
- 缓存命中状态
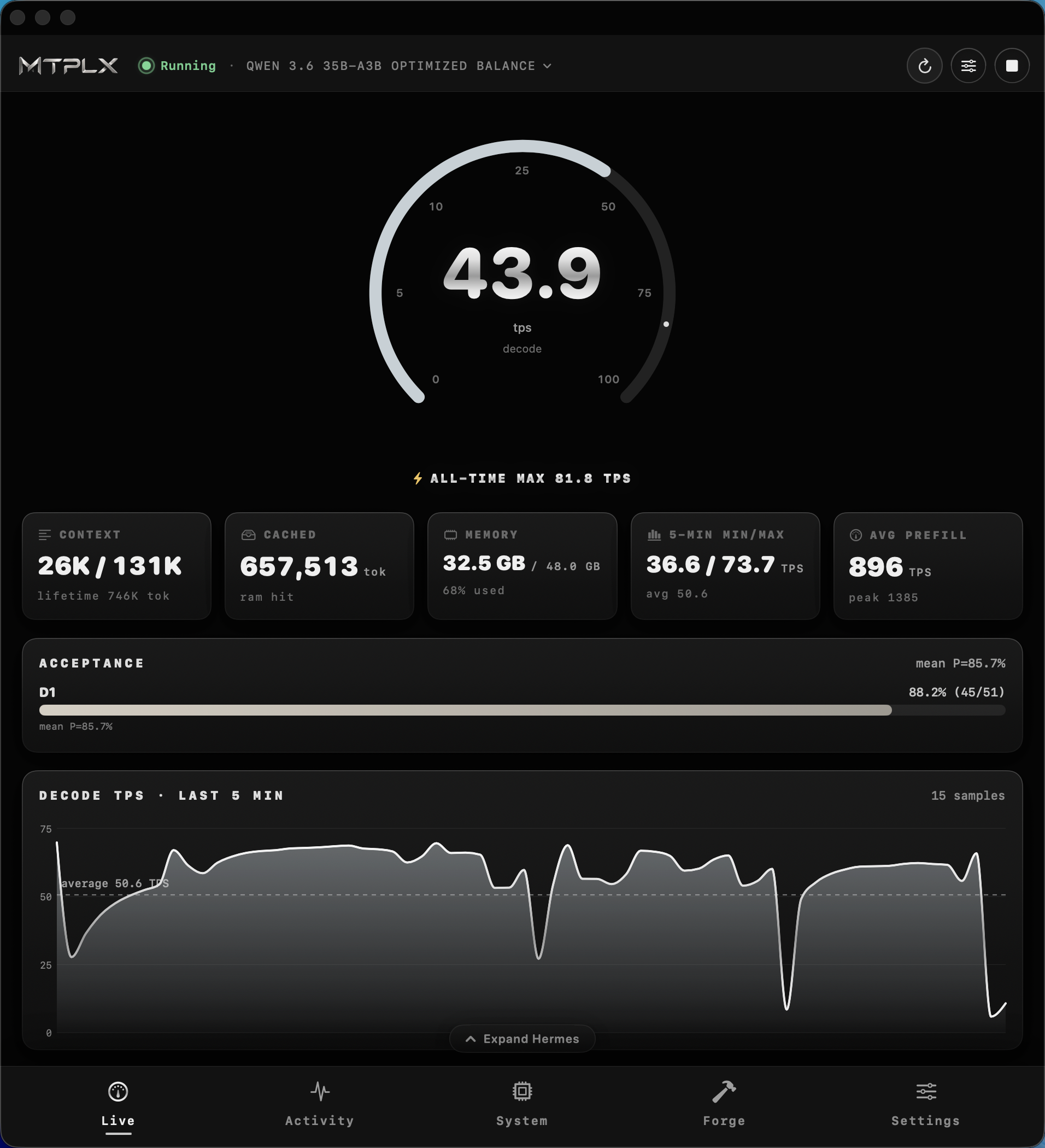
第七步:性能调优
运行 mtplx tune 自动找到最佳 MTP 深度。结果会保存,每次启动自动使用最佳配置。
性能对比:MTPLX vs omlx
在 Apple Silicon 生态中,omlx(由 Jun Kim 开发,GitHub 16,000+ Stars)是目前最流行的 LLM 推理引擎之一。它提供了多模型管理、分层 KV 缓存和 macOS 菜单栏管理等出色特性。那么 MTPLX 和它相比如何?
特性对比
| 维度 | MTPLX | omlx |
|---|---|---|
| 加速技术 | Native MTP 投机解码(无需外部草案模型) | 标准自回归解码 + 连续批处理 |
| 模型格式 | MLX(支持自定义 MTP 适配器) | MLX(社区标准格式) |
| 输出质量 | 精确拒绝采样,与 AR 输出一致 | 标准采样,输出正常 |
| API | OpenAI + Anthropic 双协议 | OpenAI 协议 |
| 界面 | macOS 原生 App + 内置 Chat + Dashboard | macOS 菜单栏 App + Web Admin Panel |
| 服务器 | 单模型高性能 | 多模型并排管理(LLM/VLM/Embedding/Reranker) |
| 缓存 | Warm-prefix session bank + SSD 缓存 | 分级 KV 缓存(内存热缓存 + SSD 冷缓存) |
| 安装 | DMG / Homebrew / pip | DMG / Homebrew / pip |
| 开源协议 | Apache 2.0 | Apache 2.0 |
| GitHub Stars | ~730+ | ~16,500+ |
性能数据对比
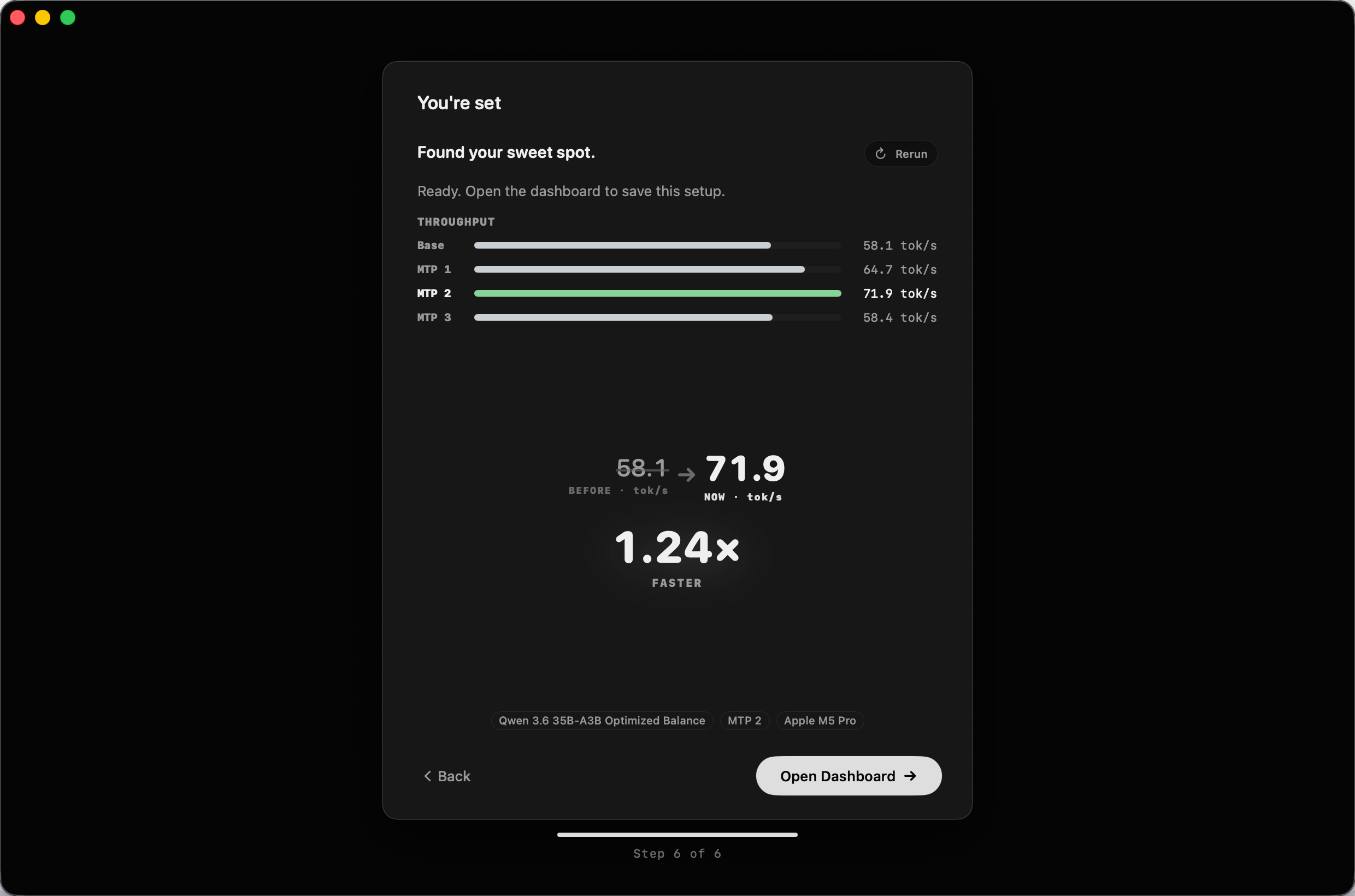
MTPLX 实测(M5 Pro, 48GB, Qwen3.6-35B-A3B):
- 标准 AR 解码: 67.5 tok/s
- MTP D1: 79.2 tok/s(+17%)
- 加速比:1.17x
MTP 对比 AR 的加速效果截图:
omlx 社区基准数据(来自 omlx.ai/benchmarks,用户提交):
| 芯片 | 内存 | 模型 | TG tok/s |
|---|---|---|---|
| M5 (10c) | 32GB | Qwen3.6-35B-A3B 4bit | 39.9-40.8 |
| M3 Max (30c) | 96GB | Qwen3.6-35B-A3B 4bit | 90.7-95.4 |
| M4 Pro (20c) | 48GB | Qwen3.5-27B 4bit | 13.7-14.4 |
深入解读
从解码速度来看:
MTPLX 的核心优势在于 MTP 投机解码。在同等硬件条件下,MTPLX 开启 MTP 后比标准 AR 解码快 17%~124%(取决于芯片型号和模型大小)。这是因为 MTP 让每一步多生成几个 token,充分利用了 GPU 的并行计算能力。
而 omlx 使用标准的自回归解码,虽然也做了大量优化(连续批处理、KV 缓存管理等),但没有从根本上改变逐 token 生成的瓶颈——每个 token 必须等前一个 token 完成。
从功能丰富度来看:
omlx 在多模型管理方面更有优势。它支持同时加载多个模型(LLM、VLM、Embedding、Reranker),并自动根据请求切换。它的分层 KV 缓存(内存热缓存 + SSD 冷缓存)在大规模对话场景下非常实用。
MTPLX 则更专注于单模型的极致性能。它的 MTP 技术、Auto-tune、Forge 都是为了让每个 token 生成得更快。
不是一个维度的竞争:
与其说 MTPLX 是 omlx 的替代品,不如说它们代表了两种不同的设计理念:
- omlx 追求 多模型编排和管理 的全能型
- MTPLX 追求 单模型推理速度 的极致型
两者可以共存:用 MTPLX 跑 Qwen 3.5/3.6 等支持 MTP 的模型,用 omlx 跑其他 MLX 模型。
总结:为什么推荐 MTPLX
理由一:⚡ 真正意义上的「不改变输出质量的加速」
MTPLX 不是通过量化或模型压缩来加速,而是通过更高效地利用 GPU 计算资源来实现加速。数学上保证了精确的拒绝采样,你的 temperature=0.6, top_p=0.95 输出的结果与标准解码完全一致。不会有「为了速度牺牲质量」的顾虑。
理由二:🔬 Native MTP 是未被发掘的金矿
Qwen 3.5/3.6 的训练过程中已经投入了算力来训练 MTP 头,但几乎没有其他推理引擎利用它们。MTPLX 将这部分能力释放出来,在几乎是零额外成本的情况下获得 17%~124% 的性能提升。
理由三:🛠️ 工具链完整,开箱即用
从下载 App 到跑起一个本地推理服务器,MTPLX 的流程非常顺畅。Auto-tune 自动找到最佳配置,Forge 让你可以打造自己的 MTP 模型,内置 Chat 和 Dashboard 让使用体验更直观。即使是非技术用户也能轻松上手。
理由四:📈 开源社区的活力
MTPLX 从 2026 年 5 月 2 日发布到 6 月 12 日,短短一个多月就获得了 700+ Stars,版本号已达 v1.0.3。作者 Youssof Altoukhi 对 Issue 的响应速度极快,修复 bug 的效率很高,社区的活跃度持续攀升。
理由五:🔮 面向未来的设计
随着更多模型厂商在训练中加入 MTP 头(Qwen 3.5/3.6 已支持,Qwen 3.7/4.0 预计也会延续),MTPLX 的技术路线将越来越有价值。它不是一时的取巧,而是抓住了模型架构演进的方向。
适合人群
- 希望充分利用 Apple Silicon 推理性能的 Mac 用户
- 使用 Qwen 3.5/3.6 系列模型的开发者
- 追求低延迟推理的 Claude Code / Cline 等工具使用者
- 想在本地跑模型同时获得云端感受的 AI 爱好者
不适合人群
- 需要使用非 Qwen/Gemma 等不支持 MTP 的模型 → omlx 或 mlx-lm 可能更合适
- 需要同时运行多个模型的服务端场景 → omlx 的多模型管理更便利
- 没有 Apple Silicon 硬件的用户 → MTPLX 是 Apple Silicon 专属
如果你拥有 Apple Silicon Mac,并且正在使用 Qwen 3.5/3.6 系列模型,MTPLX 可能是目前你能找到的最快的推理引擎。而它开箱即用的体验和活跃的社区支持,让它成为本地 AI 推理工具箱中的一柄利器。
📥 下载地址:mtplx.com 📖 GitHub:github.com/youssofal/MTPLX 🏠 官网:mtplx.com